Empower the future of Intelligence
Maximize every TFLOPS with our intelligent GPU orchestration built
for AI native business.
We don't just provide compute, we are the growth partner for your
inference at scale.





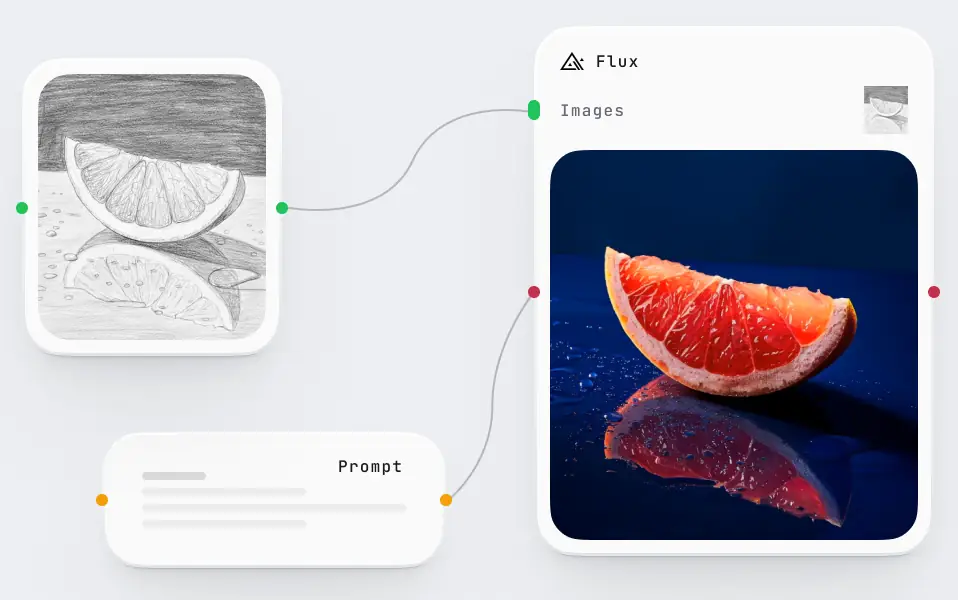
Highly elastic cost-efficient powerful compute
for AI inference & large-scale data processing

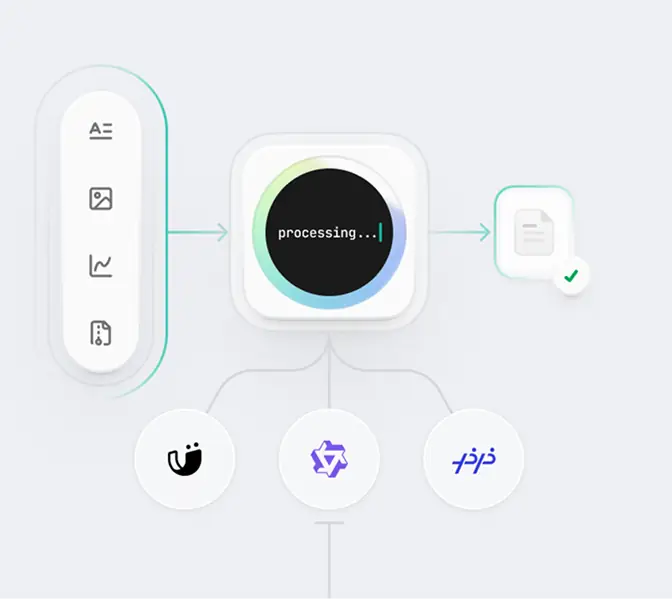


Enterprise-Grade Elastic Compute
Zero queue at peak compute demand
Intelligent auto scaling to handle traffic spikes
Second-level scaling of compute nodes, pay-as-you-go
Massive GPU pool always available
Abundant GPU resources to power your business with strong performance
Extreme cost efficiency for max value
Real-time price comparison of RTX 4090 / 24GB across platforms
End-to-end security and stability
Multi-cloud real-time redundancy, production-grade SLA ensuring uptime and
data protection
Docker ecosystem & 0 ops required
One-click image upload, Instant service deployment
Compute Product Matrix

Serverless
Auto scaling adjusts node count dynamically to match traffic fluctuations.
Eliminate idle costs and resource bottlenecks. Use cases: Production
services, traffic bursts, online applications.

Batch Job
Intelligent batch processing with priority scheduling & automated queue
management, ensuring critical tasks get resources first. Use cases:
Large-scale data processing, offline rendering, scheduled task queues.

Cloud Virtual Machine
Cloud-based AI development workstation with a complete environment - code
anytime, anywhere. Use cases: Development, testing, training, long-term
projects.

Bare Metal
Short-term rental of dedicated physical machines for maximum performance
with zero virtualization overhead. Use cases: High-end rendering, HPC
workloads.
Proven by Performance, Backed by Data
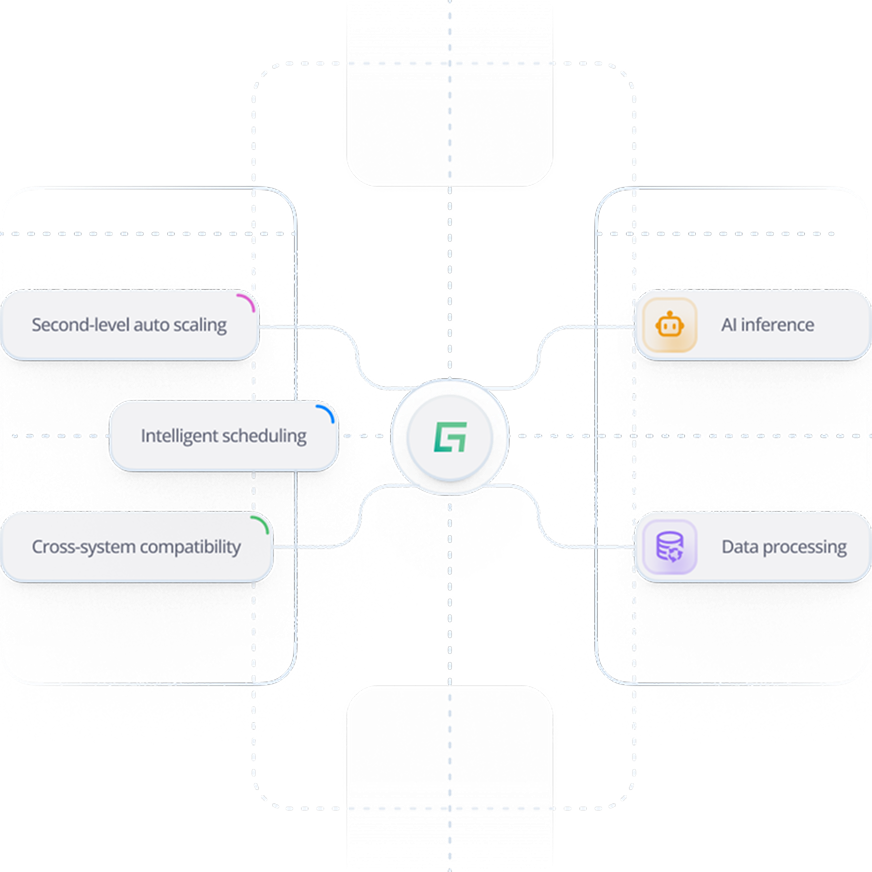
Pioneering a grid-style compute scheduling network to smooth peak demand & optimize resource utilization.
From zero to one, we designed and built the world’s first idle compute scheduling platform. Integrating 700,000+ compute resources worldwide
Proven scale
Data center connected
Scheduling operations completed
Expert-led support
Trusted by teams of all sizes
Custmer’s cost reduced by
Compute reliability
Proven by Performance, Backed by Data
Pioneering a grid-style compute scheduling network to smooth peak demand & optimize resource utilization.
From zero to one, we designed and built the world’s first idle compute scheduling platform. Integrating 700,000+ compute resources worldwide
Proven scale
Data center connected
Scheduling operations completed
Expert-led support
Trusted by teams of all sizes
Custmer’s cost reduced by
Compute reliability